
唯美瑞士·风景如画
距离上次旅行又双叒一年了,没勇气感慨时间飞快,因为我今年过得很颓废,『间歇性踌躇满志,持续性混吃等死』是我没错了,一堆烦心事短时间是难解了的,但『每年至少旅行一次』的小目标不能落空啊,是时候出去走走了。前阵子刷抖音,各种安利瑞士的视频看得心痒痒,本来就超爱漂亮的自然风景,就瑞士了!这次行程我完全是无脑跟游,嘿嘿~(•̀⌄•́)
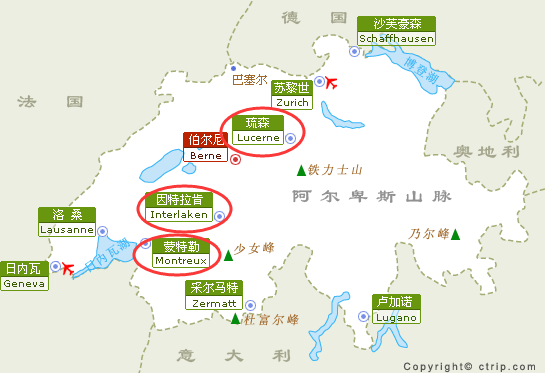 这次主要去了图中mark的三个地方:卢塞恩->因特拉肯->蒙特勒。
这次主要去了图中mark的三个地方:卢塞恩->因特拉肯->蒙特勒。
卢塞恩
从香港飞,在苏黎世落脚一晚,到达苏黎世是当地时间18点半,第一次坐10几个小时的飞机,累半死,6个小时的时差,国内已经凌晨了,假期时间变慢就是赚了的感觉,彼时深圳还在过30多度的夏天,到这边之后换秋装都瑟瑟发抖,一天入冬了。第二天坐火车往卢塞恩,坐火车发现报站语言不止英语,原来瑞士有4种官方语言,卢塞恩是德语区,隐约意识到吃饭点菜是个问题。。。到达check in之后,在廊桥附近闲逛,天气有点阴郁,整个小镇静谧而悠闲,感觉时光也慢慢流,大抵欧洲小镇都如此。


标志性的廊桥,day and night,还没来前在游记看有人说坐在湖边看风景很惬意,眼前的一切真实还原了我yy的画面,站在廊桥,看着湖里的天鹅和船艇放空,湖边尽是悠闲漫步的路人,再来一杯咖啡就演足了。


还有大名鼎鼎的悲伤的狮子石雕,位置有点难找,在一个小公园里面,瑞士这边街头很多各种水龙头,据说除特殊标示,都可以直接饮用,可见水质环境很好,依云在这边便宜是有道理的。

琉森桥附近的钟楼,登上去可以俯瞰整个小镇。


第二天终于放晴了,天公作美,正好今天要上皮拉图山,先坐游船到山脚,蓝天白云碧湖,沿途都是美景,半山都是草地,稀稀疏疏的房子,此处应开启多图模式~




大约1h到达山脚,坐小火车上山,有swiss pass可以半价购票(今年之前swiss pass是免费的),游客略多,所见黑发的基本都是中国人or韩国人,据说国庆期间韩国刚好也是假期,且瑞士对韩国免签,难怪了。




美得一塌糊涂,各种拍照,还遇到中国大妈在山顶直播
因特拉肯
去因特拉肯,就要坐心心念念的黄金列车了,略遗憾的是不能开窗,加之天气阴,不能完全还原它的美,下图就是抖音上瑞士很火的地方之一了——龙江小镇,路过mark

接近格林德瓦一段都是雪山,下车出站环顾四面都是雪顶山,半坡以下却是绿油油的草地,简直符合所有我对美的想象,满心兴奋!冷的感觉顾不上!必须拍拍拍!酒店小哥很nice,check in时生怕听不懂,特意慢语速,听到”with balcony, mountain view”很惊喜,打开房间门,真的是哇!阳台对面就是梦幻山坡,躺床上就能看见的视角,超预期的满意,因特拉肯这几天住的酒店应该是此行性价比最高的,毕竟欧洲住宿真心贵,7 8百一晚感觉还不如国内的如家。

换上羽绒服之后,沿着downtown一路漫逛,空气很清新,夹着雪水和草的味道,依稀的铃铛声,远近的牛羊在吃草,脖子上的铃铛在摇动,雪顶山上雾气缭绕,简直人间天堂。



来因特拉肯就是为了上少女峰,我们是直接在格林德瓦搭火车上去(swiss pass打7.5折之后还是觉得贵),沿途都是白雪皑皑,冷杉树一片,童话世界的样子,在海拔这么高的山开隧道,建观景台滑雪场什么的,真的很不容易,上去之后我能理解票价了。作为一个南方人,人生中第一次摸到雪,恨不得在雪地打几个滚,要不是没戴手套,还能滚雪球堆雪人了。




这是下山时,中途下站的一处拍的,夹谷之间的绿洲,视角很好。如果卢塞恩是开胃菜,因特拉肯就是硬菜,杠杠的视觉盛宴~

蒙特勒
这次行程除了瑞士之外,还有意大利,来蒙特勒的理由似乎是因为蒙特勒可以直达米兰,却意外收获瑞士行的这道甜品,不愧是天堂国家,随便哪里都美如画,蒙特勒是法语区,也多了一丝浪漫的调调,有超大的日内瓦湖,时间关系我们只坐船游了湖的一角,看了很美的日落,残红的夕阳,桃红色的金边云倒影的湖面上,白天鹅悠闲的拨掌划水,飞鸟追着夕阳的余晖戏水。我可能要变身诗人了(●´∀`●)



酒店附近的一家法国餐厅,味道不错,发现欧洲这边的餐厅菜单基本都没图,英语还能指望看得懂几个单词,法语只能求翻译了,随便赞下老东家百度的拍图翻译比Google好使多了。
来一段微信的小视频~
瑞士,一个完全符合我对美所有想象的国度,风景如画,喜欢这里悠闲慢慢的生活节奏,我一定会再来的!